Completing Version 2: Trip Distance
Version 2 of our dataset is really coming together now that we have added two new columns to it. We only have one more column to add before we can get our project on to the next stage. With new columns for day of the week and ride lengths added the dataset, we now need to add a column for the distance confirmed traveled in each ride.
Our original dataset only offers data on where a ride started and where it ended. To get an estimate on the distance traveled for each ride, our best bet is to calculate the distance from the starting point and end point. Remember, some rides are bound to come up with a distance value of 0, because the rider started at a particular station and then returned the bike to that same station. Though this illustrates the flaws with using this metric as a way to measure the distance traveled in each ride, it actually helps us to better understand the travel habits of our riders.
Another thing to keep in mind about using “Point A” and “Point B” locational coordinates is that, on their own, they cannot tell you much road would have to be traveled to get between points. These coordinates can only tell us the geospatial distance between points. The distance values we will be generating in our new column should only be used as a rough estimate of how far our riders tend to travel away from their starting point. To be more precise, its a rough measure of how far away they are willing to return their bikes relative to the place where they first began their journey.
With all of those considerations taken into account, let’s go about making our “Trip Distance in Miles” column. Since we don’t want to have a column name that is too long (and because we want to work within the syntax of the R language), we will abbreviate the name of our column to “trip_dist_miles”. Starting off right where we left off on the “Basic-Formatting-Page” file, we will add the new column by typing in the code for declaring a column in R and typing our desired name for the column into our January dataset:
jan_21_v2$trip_dist_miles <-
Don’t forget to point an arrow indicated that the code following our column name will be the data inside of the column. Make an arrow pointing left by using the left arrow key and a hyphen (<- ).
Typing the rest of the line for this code will be a bit more complicated than anything else that we have done to the dataset thus far. In order to calculate the geospatial distance between two sets of longitudinal and latitudinal coordinates in R, we are going to need a special function that can read such coordinates. Luckily, the geosphere package in R provides this in a special function called distHaversine().
Make sure that you have the geosphere package loaded into R before you move forward with this function. It is also important to load the other packages listed in previous posts before continuing. To play it safe, it is best to just load all of the packages in our “Loading-Page”.
The distHaversine() function works by nesting the coordinate data inside of it. It should have one set of coordinates, followed by another set. The way we can do this for our dataset is by entering the name of a given spreadsheet, placing a pair of brackets next to it, then placing an array with the names of the columns with our longitudinal and latitudinal data inside the brackets. We do this once for the starting data, and then once again for the end point data, separating both with a comma before closing out the parenthesis of the function.
I know that all probably went over your head if you are not familiar with the R language. Don’t worry, I will break all of that information down.
Within distHaversine(), we will need to place the data for two points: the starting point and the ending point. Our dataset has this data listed in columns for latitude and longitude, with both the start point and end point having a set of coordinates. This results in there being four columns for our coordinate data. These columns are named: start_lat, start_lng, end_lat, and end_lng.
We can use those four columns to pull up the coordinate data for the starting point and ending point of each ride in the dataset. In order to plug these columns into distHaversine(), we will need to first call the name of our spreadsheet into the function for both the start point and the endpoint. For each point, we will put a set of brackets next to the name of the spreadsheet. Within each set of brackets, an array will list the columns used to bring up the coordinates for our starting point and our endpoint.
An array is a list of values that we can bring up in our code. Arrays are made by using the c() function, with the values we wish to list nested inside of it and separated by commas.
The array for our starting point would be:
c(“start_lat”, “start_lng”)
The array for our end point would be:
c(“end_lat”, “end_lng”)
Going back to our distHaversine() function, we would nest our arrays next to the brackets that we have typed for the starting point and end point of our spreadsheet, respectively. The result should look like this:
distHaversine(jan_21_v2[c(“start_lat”, “start_lng”)], jan_21_v2[c(“end_lat”, “end_lng”)])
This code chunk creates the data for our new column. There are two problems with it, though. First, the distance values that this function would generate would have no limit to the decimal places that would be listed to show the exact distance between points. Second, the distance value would be in meters, but we want them in miles.
We can address both issues with our current distHaversine() function by nesting the entire code chunk inside a round() function.
The round() function works by nesting inside of it the value or data that you wish to round off, followed by the number of spaces behind the decimal point that you want to round off to. We will have three decimal places behind our decimal, so we will enter in a value of 3.
We can place our distHaversine() function inside of the round() function, followed by a value of 3. This would round up every value in our “trip_dist_miles” column up to two decimal points. The resulting code chunk would look like this:
round(distHaversine(jan_21_v2[c(“start_lat”, “start_lng”)], jan_21_v2[c(“end_lat”, “end_lng”)]) , 3)
In order to convert our distance values from meters into miles, we will need to add a simple mathematical equation into our round() function. To convert a meter value into miles, we have to first divide that number by 1000 (to get a kilometer) and then multiply that by 0.6213712. In R, the division symbol is “/” and the multiplication symbol is “*”. We would place our equation directly behind the distHaversine() function that we have nested inside of round(), making sure to contain that before the comma separating distHaversine() from the 3 value for our decimal places.
We now have a completed line of code that will create our new “trip_dist_miles” column! The code junk for our January spreadsheet should look like this:
jan_21_v2$trip_dist_miles <- round(distHaversine(jan_21_v2[, c(“start_lng”, “start_lat”)], jan_21_v2[, c(“end_lng”, “end_lat”)])/1000*0.6213712, 3)
We should use a view() function to see the results of our code. A window should pop showing this:
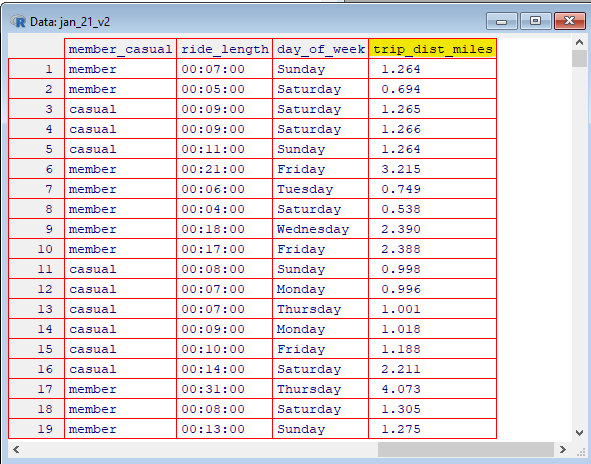
So far the code for our Version 2 of the January spreadsheet has a line for our “Day of the Week” column, a line for our “Trip Distance in Miles” column, and a line to view the results of our code. The code for our January spreadsheet should look something line this:
jan_21_v2$day_of_week <- weekdays(mdy_hm(jan_21_v2$started_at))
jan_21_v2$trip_dist_miles <- round(distHaversine(jan_21_v2[, c(“start_lng”, “start_lat”)], jan_21_v2[, c(“end_lng”, “end_lat”)])/1000*0.6213712, 3)
View(jan_21_v2)
Once we have replicated these results for the other months in 2021, we will have a Version 2 completed for every spreadsheet of the year. In the next post, we will go over getting our Version 2 dataset prepared for the next phase in our analysis.